Well folks, this is it. Seeing as I don't actually live in Seattle anymore, my blog name (and url) would be a lie within a lie. As previously promised, here is my new blog:
http://ryantwopointoh.blogspot.com/
See you there!
Monday, October 13, 2008
Friday, August 01, 2008
Upcoming: Ryan 2.0
Wherein I move to San Francisco (the city itself) and take a new job at Stumbleupon leaving my time in corporate giants (first Amazon, then Google) and kick ass and take names in a 35 person company.
Look forward to philosophical discussions about software construction, production creation, the innovators dillema and the joys of getting things done without meetings.
New web destination upcoming, look for it!
Look forward to philosophical discussions about software construction, production creation, the innovators dillema and the joys of getting things done without meetings.
New web destination upcoming, look for it!
Saturday, June 14, 2008
The post wherein I trash Rails and make many new friends
So I've been coding Web UIs with this nifty port of Rails my coworker did. It's great - really great, a solid productive environment, Javascript is great to program in, and things are mostly working out well. Except when they aren't, and lately I've come to realize that the programmatic model that Rails foists on to you is not at all suitable for advanced web UIs.
When I talk about advanced web UIs I'm talking about single-page type of web apps. The goal of such apps is not to provide an progressively degraded experience, but to push the envelope of what is even possible in a browser. I'm talking about the gmails, the Google Analytics, etc.
One fundamental problem is that Rails provides a really really good server-side templating. This is great when you are doing a simple form-and-post with remoting type of application. The structure tends to lead you to an architecture where you end up passing snippets of HTML between the server and doing innerHTML replacements on the client.
The problem with this is it's hard to disentangle the server and client presentation side of things. Sometimes your server composes the text - and handles the i18n issues - and sometimes you need to compose text and DOM on the client side. The latter can happen when you are handling errors during AJAX events - you don't want to handle an AJAX error by calling the server. So now you need to pass string tables or hidden divs with your messages in the original page. This isn't a great and integrated i18n development method.
If your goal is to create a single-page client-side stateful application, you will quickly run in to the situation where you require some form of client-side UI generation. One example is dialogs - generally they use floating divs and the JavaScript APIs tend to require HTML text snippets. Your choice is to either do some kind of client-side templating, or use the server side to pre-render in to hidden elements.
The former strategy is valid, and there are many frameworks to help you. However, this does not use the strengths of Rails. You are bypassing the entire html and model binding code, tossing away major strengths and self-crippling Rails. So why use Rails?
The second strategy is also valid, but becomes difficult to manage. You tend to need unique IDs when using fieldsets, but you'll end up having several copies of the same nodes in the dom. So now you need to swizzle IDs or move elements around. If this is starting to sound like assembly language work that is because it is.
Taking the two approaches and using i18n, you now have more issues. In the client-side templating you now need to selectively download string tables and do substitution at run time to internationalize your application. There are matters of performance - extra functional calls, hash lookups, extra HTTP gets.
In the server-generated option, things get substantially more complicated. The server-side Rails i18n situation is not entirely clear, and it still doesn't provide a framework for client-side translated strings. You can do things like JSON data from the server, but you end up manually shuttling all the strings you need from the server to the client in hidden elements or script blocks. Internationalization is hard enough without doing lots of manual work by hand.
The problem isn't that Rails isn't a productive framework, or that it doesn't do what it does well - it certainly does. The problem I found is the framework leads you to writing hybrid server-generated UIs. Furthermore, the framework tends to encourage full page refreshes. It's a matter of what is easy to do - then when you are under the gun, you do what is easiest and you end up in a multi-page application (like ours) when you really wanted a single page application. The path forward is not clear, and Rails isn't really helping here.
When I talk about advanced web UIs I'm talking about single-page type of web apps. The goal of such apps is not to provide an progressively degraded experience, but to push the envelope of what is even possible in a browser. I'm talking about the gmails, the Google Analytics, etc.
One fundamental problem is that Rails provides a really really good server-side templating. This is great when you are doing a simple form-and-post with remoting type of application. The structure tends to lead you to an architecture where you end up passing snippets of HTML between the server and doing innerHTML replacements on the client.
The problem with this is it's hard to disentangle the server and client presentation side of things. Sometimes your server composes the text - and handles the i18n issues - and sometimes you need to compose text and DOM on the client side. The latter can happen when you are handling errors during AJAX events - you don't want to handle an AJAX error by calling the server. So now you need to pass string tables or hidden divs with your messages in the original page. This isn't a great and integrated i18n development method.
If your goal is to create a single-page client-side stateful application, you will quickly run in to the situation where you require some form of client-side UI generation. One example is dialogs - generally they use floating divs and the JavaScript APIs tend to require HTML text snippets. Your choice is to either do some kind of client-side templating, or use the server side to pre-render in to hidden elements.
The former strategy is valid, and there are many frameworks to help you. However, this does not use the strengths of Rails. You are bypassing the entire html and model binding code, tossing away major strengths and self-crippling Rails. So why use Rails?
The second strategy is also valid, but becomes difficult to manage. You tend to need unique IDs when using fieldsets, but you'll end up having several copies of the same nodes in the dom. So now you need to swizzle IDs or move elements around. If this is starting to sound like assembly language work that is because it is.
Taking the two approaches and using i18n, you now have more issues. In the client-side templating you now need to selectively download string tables and do substitution at run time to internationalize your application. There are matters of performance - extra functional calls, hash lookups, extra HTTP gets.
In the server-generated option, things get substantially more complicated. The server-side Rails i18n situation is not entirely clear, and it still doesn't provide a framework for client-side translated strings. You can do things like JSON data from the server, but you end up manually shuttling all the strings you need from the server to the client in hidden elements or script blocks. Internationalization is hard enough without doing lots of manual work by hand.
The problem isn't that Rails isn't a productive framework, or that it doesn't do what it does well - it certainly does. The problem I found is the framework leads you to writing hybrid server-generated UIs. Furthermore, the framework tends to encourage full page refreshes. It's a matter of what is easy to do - then when you are under the gun, you do what is easiest and you end up in a multi-page application (like ours) when you really wanted a single page application. The path forward is not clear, and Rails isn't really helping here.
Friday, June 13, 2008
Google I/O Videos
The Google I/O 2008 sessions are now online. Included are slides and Youtube videos of a variety of topics, including Android, Open Social, GWT, Javascript and Maps.
If you were unable to attend, I highly recommend the videos.
Check out GWT extreme as an exciting example of the kinds of things you can do with JS and browsers:
Tuesday, June 03, 2008
CSS Performance
I have been reading CSS Mastery lately - its a great medium/advanced guide to CSS. If you know roughly about CSS but you need serious helping turning that in to mastery, then this book is for you. The book provides both a quick introduction and specific solutions. However, the book provides advice that may be at odds with Firefox performance guidelines.
The book starts with a quick introduction, and then delves in to the CSS box model, then straight in to rounded corner techniques. It provides pragmatic advice along the way - such as what works on which browsers and making design cross-browser.
However, the book recommends avoiding the use of too many classes - calling that design "classitus". By using the descent selector you can target your styles without using too many classes. If you read the mozilla developer guide to efficient CSS, the advice there is substantially different.
The guide advises, among other things, that the descendant selector has poor performance. They recommendation is to use targeted class styles instead. This may lead to an expanded use of classes in your application, but the performance increase may be worth it. The best strategy is to measure. Since querying certain properties will block until the CSS styling is finished, you can measure the performance with code like so:
var start = new Date().getTime();
element.innerHTML = 'a ton of html and css';
var w = element.offsetWidth;
var end = new Date().getTime();
alert(end - start);
Thanks to my Nameless Coworker who shared those tips via email.
Remember: always measure before you attempt any performance optimizing. That way you can be sure your hard work has ultimately benefited the end user.
The book starts with a quick introduction, and then delves in to the CSS box model, then straight in to rounded corner techniques. It provides pragmatic advice along the way - such as what works on which browsers and making design cross-browser.
However, the book recommends avoiding the use of too many classes - calling that design "classitus". By using the descent selector you can target your styles without using too many classes. If you read the mozilla developer guide to efficient CSS, the advice there is substantially different.
The guide advises, among other things, that the descendant selector has poor performance. They recommendation is to use targeted class styles instead. This may lead to an expanded use of classes in your application, but the performance increase may be worth it. The best strategy is to measure. Since querying certain properties will block until the CSS styling is finished, you can measure the performance with code like so:
var start = new Date().getTime();
element.innerHTML = 'a ton of html and css';
var w = element.offsetWidth;
var end = new Date().getTime();
alert(end - start);
Thanks to my Nameless Coworker who shared those tips via email.
Remember: always measure before you attempt any performance optimizing. That way you can be sure your hard work has ultimately benefited the end user.
On GWT - Welcome Visitors
Hi visitors from onGWT.com! I see my lowly blog has about 30x the traffic it normally does. I guess I struck a nerve a bit.
Currently I'm still investigating GWT. I haven't started production coding, and it may be a few months before I get prod GWT code out there, but it will happen at some point.
In the mean time, I hope to post tips and hints about my GWT experience and how to achieve elegant and performant web UIs.
Currently I'm still investigating GWT. I haven't started production coding, and it may be a few months before I get prod GWT code out there, but it will happen at some point.
In the mean time, I hope to post tips and hints about my GWT experience and how to achieve elegant and performant web UIs.
Monday, June 02, 2008
Google I/O recap and summary
Well Google I/O is over. Hopefully there will be another one next year - the conference was great value, and had scores of smart people talking about interesting web things. I attended in part to learn about GWT. Initially I was very sceptical about the value proposition of GWT - compiling Java to JavaScript? Get real! Programming in a static language like Java? Two steps backwards!
Despite these disadvantages, I have come full circle and I now firmly believe that GWT is an excellent platform for advanced web apps. There are a few reasons why I now strongly believe this:
Most JS libraries that abstract browser differences do so by adding adapter layers, or annotating the built-in prototypes to create a new development approach. However, the practical realities of JavaScript performance don't encourage the use of extra function calls or closures. Using a Prototype example:
$('ul#myList li').each(function(li) {
// do something with each list element, possibly using a closed over variable
});
While elegant, this is not nearly as performant as more basic code:
var myList = document.getElementById('myList').getElementsByTagName('li');
for (var i = 0, il = myList.length; i < il ; i++) {
// do something with each list element, no closure necessary.
}
While in theory 'each' should know about the best way to loop over an array, you also incur the cost of two user function calls, and a closure. These are not free, even as they improve the code - mis-coding loops is a major cause of bugs.
Given that most JavaScript runtimes are interpreted (we are starting to see the rumbles of VMs for JavaScript), adding extra calls and object allocations is not free. Add these up and eventually the weight of your JS application will grind browsers to a halt.
While nothing is ultimately a panacea - better tools are always better. Increasing the level of your abstractions and letting the computer do the work for you is always better. It seems like JavaScript is becoming the new assembly language - and we all know how much demand there is for assembly language programmers these days.
If you found this useful, maybe my article on making CSS performant might interest you?
Despite these disadvantages, I have come full circle and I now firmly believe that GWT is an excellent platform for advanced web apps. There are a few reasons why I now strongly believe this:
- GWT has a form of late binding - allowing differing implementations for each browser platform.
- GWT has good optimized support (in 1.5) for overlaying Java objects on to JSON objects, providing an elegant and efficient method of consuming JSON data.
- Excellent and complex products are being produced in GWT, the kind I'd like to develop.
- Good abstraction over browser quirks in a optimizing manner, as well as allowing for writing code in a abstract way.
Most JS libraries that abstract browser differences do so by adding adapter layers, or annotating the built-in prototypes to create a new development approach. However, the practical realities of JavaScript performance don't encourage the use of extra function calls or closures. Using a Prototype example:
$('ul#myList li').each(function(li) {
// do something with each list element, possibly using a closed over variable
});
While elegant, this is not nearly as performant as more basic code:
var myList = document.getElementById('myList').getElementsByTagName('li');
for (var i = 0, il = myList.length; i < il ; i++) {
// do something with each list element, no closure necessary.
}
While in theory 'each' should know about the best way to loop over an array, you also incur the cost of two user function calls, and a closure. These are not free, even as they improve the code - mis-coding loops is a major cause of bugs.
Given that most JavaScript runtimes are interpreted (we are starting to see the rumbles of VMs for JavaScript), adding extra calls and object allocations is not free. Add these up and eventually the weight of your JS application will grind browsers to a halt.
While nothing is ultimately a panacea - better tools are always better. Increasing the level of your abstractions and letting the computer do the work for you is always better. It seems like JavaScript is becoming the new assembly language - and we all know how much demand there is for assembly language programmers these days.
If you found this useful, maybe my article on making CSS performant might interest you?
Wednesday, May 28, 2008
Google I/O: OpenSocial
Here are my "raw" notes from the OpenSocial intro session at 11:15am:
Open Social.
Introduction. How to build OpenSocial Apps. OS Containers. (more)
Patrick: Intro.
Make the web better: by making it social. What does 'social' mean? Ask kids. His daughter: We look at each other, we talk, we laugh, we help each other, we read together, we do projects together. (cute kid pictures)
Raoul - kids toy, the "social object" - take home from school, do things with it, take pictures, create a social event around it.
Jaiku's Jyri Engeström's 5 rules for social networks: social projects
1. what is your object?
2. what are your verbs?
3. how can people share the objects?
4. what is the gift in the invitation?
5. are you charging the publishers or the spectators?
http://tinyurl.com/yus8gw
How do we socialize objects online without having to create yet another social network?
OpenSocial is a straightforward application of chapters 8 and 9 of his 1998 book "Information Rules".
"Standards change competition for a market to competition within a market."
OpenSocial Foundation - http://opensocial.org/ Keep the specification open. Discussed in public forum. Evolves in a open source community process.
80% of your code is common to every site/network. The other 20% are specializing for each site.
Standards based: html+javascript+rest+oauth
Chris Schalk: How to build an OpenSocial application.
Javascript API:
- People & Friends.
- Activities
- Persistence
-- provide state without a server.
-- share data with your friends
-- up to container (ie: site)
Key concept: OpenSocial "container" - basically a website where your OpenSocial application runs. Provides services to your application.
Async APIs - make request, provide callback, use data.
Data storage: Async hashmap system. Callback function provides notice of success.
REST API uses Atom format.
Establish a "home" site where gadget can phone home to retrieve data. Hosted on various sites, including AppEngine.
Kevin Marks: OpenSocial Containers.
Apps are hosted in Containers. What are they?
Containers don't choose users. Containers set up the social model, users choose to join.
- They grow through homophily and affinity
- network effect can bring unexpected userbases
Not just Social Network Sites:
- profiles and home pages
- personal dashboards
- sites based around a social object
- corporate CRM systems
- any website
Owner and Viewer are defined by Container
- The application gets IDs and connections to other IDs.
Owner need not be a person.
- could be an organization or a social object.
Kinds of container - social network sites
- profile pages
-- owner is profile page owner
-- view may not be known, may be owner or other member
- home page
-- owner is Viewer (must be logged in to see)
Examples: myspace, hi5, orkut
Kinds of container - Personal dashboard:
- like hom pages
-- owner is viewer (must be logged in)
- friends may not be defined
Examples: iGoogle, MyYahoo
Kinds of container: Social object site
- Pages reflect the object - movie, picture, product
- owner is the pboject
- owner friends are people connected to the object
- may be authors or fans
- viewer is looking at it, viewer friends are people you may want to share with.
Example:...
Kinds of container - CRM system
- pages reflect the customer
-- owner is the customer
-- owner friends are people connected to the customer
--- may be colleagues or other customers
-- viewer is you
Kinds of container - any website
- owner is site
-- owner friends are site users
- viewer is you
-- viewer friends are your friends who have visited this site
Example: Google Friend Connect.
Container Sites control Policy.
Meet the containers (next session).
Best practices for spreading your app (tomorrow).
Chris Schalk: Becoming an OpenSocial Container
Apache Shindig
- What is shindig?
-- open source software that allows you to host OpenSocial applications.
- is currently an apache software incubator project
- heavy partner involvement (Ning, hi5...)
- services as open source reference implementation of OpenSocial & gadgets technology
http://incubator.apache.org/shindig
- Example of shindig.
- Shindig is in CVS, can't download tarballs (yet).
Open Social.
Introduction. How to build OpenSocial Apps. OS Containers. (more)
Patrick: Intro.
Make the web better: by making it social. What does 'social' mean? Ask kids. His daughter: We look at each other, we talk, we laugh, we help each other, we read together, we do projects together. (cute kid pictures)
Raoul - kids toy, the "social object" - take home from school, do things with it, take pictures, create a social event around it.
Jaiku's Jyri Engeström's 5 rules for social networks: social projects
1. what is your object?
2. what are your verbs?
3. how can people share the objects?
4. what is the gift in the invitation?
5. are you charging the publishers or the spectators?
http://tinyurl.com/yus8gw
How do we socialize objects online without having to create yet another social network?
OpenSocial is a straightforward application of chapters 8 and 9 of his 1998 book "Information Rules".
"Standards change competition for a market to competition within a market."
OpenSocial Foundation - http://opensocial.org/ Keep the specification open. Discussed in public forum. Evolves in a open source community process.
80% of your code is common to every site/network. The other 20% are specializing for each site.
Standards based: html+javascript+rest+oauth
Chris Schalk: How to build an OpenSocial application.
Javascript API:
- People & Friends.
- Activities
- Persistence
-- provide state without a server.
-- share data with your friends
-- up to container (ie: site)
Key concept: OpenSocial "container" - basically a website where your OpenSocial application runs. Provides services to your application.
Async APIs - make request, provide callback, use data.
Data storage: Async hashmap system. Callback function provides notice of success.
REST API uses Atom format.
Establish a "home" site where gadget can phone home to retrieve data. Hosted on various sites, including AppEngine.
Kevin Marks: OpenSocial Containers.
Apps are hosted in Containers. What are they?
Containers don't choose users. Containers set up the social model, users choose to join.
- They grow through homophily and affinity
- network effect can bring unexpected userbases
Not just Social Network Sites:
- profiles and home pages
- personal dashboards
- sites based around a social object
- corporate CRM systems
- any website
Owner and Viewer are defined by Container
- The application gets IDs and connections to other IDs.
Owner need not be a person.
- could be an organization or a social object.
Kinds of container - social network sites
- profile pages
-- owner is profile page owner
-- view may not be known, may be owner or other member
- home page
-- owner is Viewer (must be logged in to see)
Examples: myspace, hi5, orkut
Kinds of container - Personal dashboard:
- like hom pages
-- owner is viewer (must be logged in)
- friends may not be defined
Examples: iGoogle, MyYahoo
Kinds of container: Social object site
- Pages reflect the object - movie, picture, product
- owner is the pboject
- owner friends are people connected to the object
- may be authors or fans
- viewer is looking at it, viewer friends are people you may want to share with.
Example:...
Kinds of container - CRM system
- pages reflect the customer
-- owner is the customer
-- owner friends are people connected to the customer
--- may be colleagues or other customers
-- viewer is you
Kinds of container - any website
- owner is site
-- owner friends are site users
- viewer is you
-- viewer friends are your friends who have visited this site
Example: Google Friend Connect.
Container Sites control Policy.
Meet the containers (next session).
Best practices for spreading your app (tomorrow).
Chris Schalk: Becoming an OpenSocial Container
Apache Shindig
- What is shindig?
-- open source software that allows you to host OpenSocial applications.
- is currently an apache software incubator project
- heavy partner involvement (Ning, hi5...)
- services as open source reference implementation of OpenSocial & gadgets technology
http://incubator.apache.org/shindig
- Example of shindig.
- Shindig is in CVS, can't download tarballs (yet).
Google I/O
At Google I/O in San Francisco this week. A two day developer conference covering Google's public tools and APIs.

Sunday, April 27, 2008
Email organization in GMail (Aka the Zen of Gmail)
I keep on getting friends who complain about GMail and pine for the "good old days" of Outlook.
I've received hundreds of emails a day for over 7 years. Now that I am able to use Gmail as my primary work email every day, the situation is thousands, nay, millions of times better than the "good old Outlook days". Or as they say, Outlook, not so good.
I think part of the problem is people take an email-organization mindset from Outlook and try to apply it to Gmail. The results - comedy abounds! The solution? Shed your old ways, and embrace the new!
The first thing about Gmail is it's noticeable lack of folders. Combined with a massive inbox from years of not archiving, this can quickly overwhelm people in to believing that it's impossible to organize. The problem is in the mindset, and you have to break yourself of the past.
The way to think of email is instead of 'messages' there are 'conversation threads'. All the replies and replies to replies are bound together as a single unit (the conversation) that is always available. Someone replies to a year old conversation? They whole bundle is presented so you can go back in time and check on what someone said, or maybe remind yourself of your own words (as painful as that can be sometimes). This is really the key organizational mechanism, and one I wished for many times under Outlook. This ensures you have maximum context at all times.
To organize these threads, Gmail presents a list on the right hand side. Instead of folders, think of these as 'views'. Views are always by default sorted by date. Let's run through what each one means: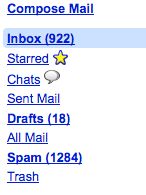
Instead, use the "e" key which always always archives a conversation, no matter where you are. And given how easy it is to type on the left hand side of the keyboard, you can hit it while your right hand is on the mouse - left hand mousers, sorry it doesn't work out!
The other key I use constantly is "u" - this is used when viewing a message, and takes you back to the previous view. Back to search results, to the inbox or some other list view of conversations. This is easier than finding the "back to search results" link or the "back to label" or other link.
The final keys I sometimes use is "[" and "]". These move you from one message to the next archiving them as you go. If you want to start at the top of your inbox and read on downwards, this is a great way to avoid visiting the list-view between every message.
With these tips, it becomes easy to clear messages out of your inbox. You can search with the additional term "l:inbox" to find messages that are in the inbox, but match any other pattern. I get livejournal notices to my inbox, so every so often I search "l:inbox livejournal", then I click on "All" - if I have more than 1 page of messages, a little message appea rs and asks me if I want to select every message. This way I can affect thousands of messages. You can use this to delete or archive or apply new labels to large numbers of messages at once.
rs and asks me if I want to select every message. This way I can affect thousands of messages. You can use this to delete or archive or apply new labels to large numbers of messages at once.
I hope these tips can help you achieve serious Gmail zen. They help me manage my massive mailbox (27,000 conversations in ~ 18 months) with minimal stress. I don't need to spend much time setting up a complex taxonomy or detailed filing mechanism, instead I can just arrange my things in to broad piles and let search help me. I have found that I personally can remember circumstances, and that is enough to let me find messages using the above search-and-organization tips.
I've received hundreds of emails a day for over 7 years. Now that I am able to use Gmail as my primary work email every day, the situation is thousands, nay, millions of times better than the "good old Outlook days". Or as they say, Outlook, not so good.
I think part of the problem is people take an email-organization mindset from Outlook and try to apply it to Gmail. The results - comedy abounds! The solution? Shed your old ways, and embrace the new!
The first thing about Gmail is it's noticeable lack of folders. Combined with a massive inbox from years of not archiving, this can quickly overwhelm people in to believing that it's impossible to organize. The problem is in the mindset, and you have to break yourself of the past.
The way to think of email is instead of 'messages' there are 'conversation threads'. All the replies and replies to replies are bound together as a single unit (the conversation) that is always available. Someone replies to a year old conversation? They whole bundle is presented so you can go back in time and check on what someone said, or maybe remind yourself of your own words (as painful as that can be sometimes). This is really the key organizational mechanism, and one I wished for many times under Outlook. This ensures you have maximum context at all times.
To organize these threads, Gmail presents a list on the right hand side. Instead of folders, think of these as 'views'. Views are always by default sorted by date. Let's run through what each one means:

- Inbox - these are the conversations labeled with the 'Inbox' label. All new email gets tagged with this label by default. So a conversation previously out of the inbox will come back when someone replies to it.
- Starred - all conversations with a star on any of the individual messages.
- Chats - some conversations are literally that, and take place via gtalk. They are easily accessible here. Offline gtalk messages come in to your inbox as well.
- Sent mail - all conversations you've replied to, or sent to. They are sorted by the time and date you replied.
- Drafts - those conversations you've saved a draft to. If you were replying to an existing conversation, the whole thing appears here (maximum context at all times).

- All Mail - this is every conversation you have.
- Spam - This is slightly special, since Spams don't appear in your Inbox or All Mail. They are auto-nuked every 30 days. Gmail has one of the best spam filters.
- Trash - Those conversations and messages you've deleted. Yes you can delete a single message out of a conversation, that option is available in the drop down menu. Messages are permanently deleted after 30 days.

- I create a label for each major focus area and mailing list. I use a single label for each project I'm involved in. As I move to new projects, I create a new label for each one. This way I can get a comprehensive project-wide view by clicking on the label views on the left-hand side of the user interface.
- Every major mailing list gets it's own label. I can bundle several mailing lists in to a single label - for example every apple and mac oriented mailing list I'm on (about 4) are labeled 'apple'. I also have a label for each major announcement list.
- Use filters for auto-labeling mailing lists. This is critical, since labeling every single message would use all day. If you want to label a mailing list, you can do so by entering "list:foobar-announce" in the 'Has the words:' field. You can then have gmail apply a label.

- Use the 'skip the inbox' feature for high volume mailing lists. Combined with 'Apply the label' option, you can quickly view those messages later without dealing with the daily flood of messages in your inbox. I use this for conversation lists that aren't important but I'd like to stay on so I can lurk when I have the time.

- My team has a team-address, so it gets a filter to automatically give it the project label. Individual messages just to me, not cc'ed need to be manually applied. Given that most emails are CCed to the team list, this doesn't happen as often as you might think.
- The 'list:name' search operator is extremely powerful. Few people know about it, but it is a power-tool for those on many mailing lists. The thing that makes this a solid knock-out is that the 'name' is actually a substring match! So for example if my team is named 'foo' then I might have the mailing lists: foo-dev, foo-reviews, foo-alerts, foo-questions. If I create a filter that applies the label 'Foo' to messages that have the words "list:foo" then all 4 mailing lists are hit with the same label.
- The other important thing about "list:" is it uses the "List-Id" header (and a few others). Compare to using a search term like "to:mailing-list" - if someone Bcc's the list, it will slip through the filter. Using "list:" and you will have an airtight set up.
- Eschew organization over search - since Gmail search is so powerful and fast, it's often better to have larger organization 'units' over being super-precise about folders and taxonomy. My super-search tips below will super-charge your Gmail experience.

- Gmail now lets you give colours to labels. This is a great way to automatically apply labels to incoming messages and they will stand out in your inbox. For example, incoming bills from your bank or cable company can be easily identified by the subject or 'from' address. Announcement lists are another good candidate for colours.
- I have a label I call "@to-me" which is automatically attached to all messages with a filter. The filter has "to:ryan@foo.com" as the criteria. Any emails that has me on the To or CC line gets this label. This way I can quickly identify those conversations that were sent to ME versus conversations that reached me via a mailing list. This is a good way to pay attention to the most important things first. And thanks to the "@" symbol it is at the top of the label list.
- Labels are not folders. This is very important, since a conversation can have multiple labels, you don't have to worry about careful taxonomies that are broken by messy forwards or when email conversations cross over.
- Use task-oriented labels - if you are in to GTD you can create various GTD labels for your email, without affecting the aforementioned classification mechanism. Labels such as "@to-me", "To-Reply", "Reply-At-Home" can coexist peacefully. You can also use labels as a way of classifying across many lines, without copying messages to multiple places, or breaking existing classification mechanisms. For example if you had a label called "Praise" which you attached to all messages where people praised your work, you would be able to find those again when review time comes around. In outlook-land I would have to copy messages or move them and I might lose messages or context.



- label:project from:joe - this looks for all emails from Joe in my project. Since Joe is a pretty common name, doing the search "from:Joe" would return too many messages. Since I know Joe is my team-mate and I was looking for that message he sent me a few weeks ago on that new feature, this cuts to the chase.
- l:inbox -l:project - this uses two major features, the "l:" shortcut for "label:", and the other is negative term-search. This returns all messages in my Inbox and that are NOT for my project. This is a good way to catch all the other "junk" (not literally, the Spam filter is pretty good) in my inbox. I can then select all the messages and archive them out of the Inbox easily.
- list:bar-announce - I don't always have labels for every single mailing list. This pulls them out of my mail in a single fast search. Even if people Bcc your mailing list, or if mailing lists are chained, this still works.
- l:inbox list:bar-announce - pick those stray messages out of your inbox and archive them easily.
- l:project l:@to-me after:2008/01/01 - all messages I sent on my project since Jan 1, 2008. You can also use "before:" as well.
- has:attachment, is:starred, filename:*.jpg - find mails with attachments, with stars, with specific filenames. These become powerful combined with previous tips. For example: "l:project filename:*.ppt from:joe" - find that presentation Joe sent you.
- By default Gmail uses and - so when you say "from:joe l:project" it means from Joe AND labeled "project". You can use "OR" (all-caps is important here) to built those complex expressions.
- Here is one I used: "l:project (subject:Code Review OR subject:Bug) -to:me". This gives messages in my project with the subject "Code Review" or "Bug" that were not addressed to me. I set this up in a filter and had these messages automatically archived so I never saw them in my inbox. This project recieved far too many code reviews and bug reports, and I only needed the ones directly addressed to me.
- Don't forget oldies but goodies such as "subject:party" and "plain old" full text search. You can search your massive mailbox in seconds for any keyword or phrase (use double-quotes).
Instead, use the "e" key which always always archives a conversation, no matter where you are. And given how easy it is to type on the left hand side of the keyboard, you can hit it while your right hand is on the mouse - left hand mousers, sorry it doesn't work out!
The other key I use constantly is "u" - this is used when viewing a message, and takes you back to the previous view. Back to search results, to the inbox or some other list view of conversations. This is easier than finding the "back to search results" link or the "back to label" or other link.
The final keys I sometimes use is "[" and "]". These move you from one message to the next archiving them as you go. If you want to start at the top of your inbox and read on downwards, this is a great way to avoid visiting the list-view between every message.
With these tips, it becomes easy to clear messages out of your inbox. You can search with the additional term "l:inbox" to find messages that are in the inbox, but match any other pattern. I get livejournal notices to my inbox, so every so often I search "l:inbox livejournal", then I click on "All" - if I have more than 1 page of messages, a little message appea
 rs and asks me if I want to select every message. This way I can affect thousands of messages. You can use this to delete or archive or apply new labels to large numbers of messages at once.
rs and asks me if I want to select every message. This way I can affect thousands of messages. You can use this to delete or archive or apply new labels to large numbers of messages at once.I hope these tips can help you achieve serious Gmail zen. They help me manage my massive mailbox (27,000 conversations in ~ 18 months) with minimal stress. I don't need to spend much time setting up a complex taxonomy or detailed filing mechanism, instead I can just arrange my things in to broad piles and let search help me. I have found that I personally can remember circumstances, and that is enough to let me find messages using the above search-and-organization tips.
Thursday, April 10, 2008
Java Programmers
I haven't met a "java programmer" who only knows Java that is awesome. They are the new VB programmers - hooking up up Java components in to amalgams of crap.
- Me, in chat to a fellow developer.
Monday, February 04, 2008
5MT: Java hating
This is not really a 5 minute thought, but more like a brief Java rant from someone else:
"I hate Java. As a programmer, I hate Java, the language, for what it has done to the field of programming. As a journalist, I hate the relentless hyping of Java by its supporters, as well as their unending excuses as to why Java has failed to deliver. And as a technologist who has been involved with three major projects that have used Java, I hate the complications that Java has caused."
-- source
"I hate Java. As a programmer, I hate Java, the language, for what it has done to the field of programming. As a journalist, I hate the relentless hyping of Java by its supporters, as well as their unending excuses as to why Java has failed to deliver. And as a technologist who has been involved with three major projects that have used Java, I hate the complications that Java has caused."
-- source
Tuesday, January 22, 2008
jPod
I've been watching the jPod TV adaptation. And while it deviates from the book in many important ways, it does maintain the same sense of insanity as the book.
Also an awesome Google sneak was in tonight's episode, I entered kambamthankyoumaam in to Google and I was rewarded with an awesome page that was straight out of the episode.
Obviously as a result of this posting I'm hoping to show up in that search results, which as of right now (11:55pm PST) is showing exactly 1 result, that being the one I linked to. Van city players, indeed.
Also an awesome Google sneak was in tonight's episode, I entered kambamthankyoumaam in to Google and I was rewarded with an awesome page that was straight out of the episode.
Obviously as a result of this posting I'm hoping to show up in that search results, which as of right now (11:55pm PST) is showing exactly 1 result, that being the one I linked to. Van city players, indeed.
Monday, January 21, 2008
5MT: Why US Debit Cards are Bunk
I was reminded yesterday about how bad debit cards are here in the US. Let me count the ways thee make me mad. Firstly is thine insistence on being a "visa" card. This is particularly bad because credit cards do not require online verification. Clerks are supposed to compare signatures to card signatures, but I rarely see this happen. It is totally possible for a fraudster with just your card number (maybe even guessed?) to create a new fake card and run some off-line transactions.
Secondly is thine non-credit card status. There are laws that protect credit card holders from fraud and limit their liability to $50. While most banks are fully willing to refund and replace money promptly when fraud amounts are low, they generally take a bit longer when the amounts are significantly high. Most credit card companies can take upwards of 90 days to resolve fraud charges in the $3-5000 range.
The root of the problem is banks are not liable for fraud on credit cards. The responsibility lies completely with the merchant. In addition to the 3% transaction fees they pay, card companies regularly "charge back" to the merchant. Charge backs can be as high as 5% of the transaction cost. So now your cost of doing business is 8% - and there is no easy way to increase security.
The solution? Turn debit cards in to real debit cards that only take online PIN-authenticated transactions. This will reduce costs for everyone since the 3% credit card charge is built in to all prices even if you pay cash.
Added:
My friend Sacha points out that PIN transactions are not immune from professional fraudsters. This reminds me that the problem with "secure" systems that really aren't is convincing the powers that be of the legitimacy of your fraudulent transaction. A real life example is the "anti theft" car systems that aren't undefeatable - despite manufacturer claims. At this point you are in an uphill fight to regain your week's meal money.
Secondly is thine non-credit card status. There are laws that protect credit card holders from fraud and limit their liability to $50. While most banks are fully willing to refund and replace money promptly when fraud amounts are low, they generally take a bit longer when the amounts are significantly high. Most credit card companies can take upwards of 90 days to resolve fraud charges in the $3-5000 range.
The root of the problem is banks are not liable for fraud on credit cards. The responsibility lies completely with the merchant. In addition to the 3% transaction fees they pay, card companies regularly "charge back" to the merchant. Charge backs can be as high as 5% of the transaction cost. So now your cost of doing business is 8% - and there is no easy way to increase security.
The solution? Turn debit cards in to real debit cards that only take online PIN-authenticated transactions. This will reduce costs for everyone since the 3% credit card charge is built in to all prices even if you pay cash.
Added:
My friend Sacha points out that PIN transactions are not immune from professional fraudsters. This reminds me that the problem with "secure" systems that really aren't is convincing the powers that be of the legitimacy of your fraudulent transaction. A real life example is the "anti theft" car systems that aren't undefeatable - despite manufacturer claims. At this point you are in an uphill fight to regain your week's meal money.
Thursday, January 17, 2008
Five minute thoughts
Thanks to the internet and TV I have a 5 minute attention span, just like everyone else it seems. Combined with blog post formats and Youtube 3 minute videos, we have a contemporary pop culture that encourages affected-ADD.
But instead of rail against that, I'll cherish it with the introduction of Ryan's Five Minute Thoughts. Designed to be readable (and writable) during a Youtube video, or (in my case) a build, they are the ultimate in cognitive adaptation.
Today's 5 Minute Thought (5MT): Comcast's Tiered Service.
TimeWarner is introducing tiered internet plans - presumably in an attempt to either restrain bandwidth usage or raise funds to, and this is highly speculative, build a better network. TW claims that 5% of the users consume 50% of the bandwidth usage. Bandwidth usage is surely only going to rise, with the rise of downloadable video from iTMS and Netflix. Right now video downloaders are a leading-edge case of internet users. Bittorrent and iTunes HD downloads is the future of media consumption.
Cable operators are in an interesting position of offering "unlimited" bandwidth that really isn't. Looks like TW has decided this is untenable and decided to take this leading-edge case as exactly that. Right now it's 5% that consumes half, but soon it will be 25% that consumes 99%. At that point you can't realistically cut off a quarter of your userbase. Given the dim outlook for cable companies and subscriber growth it might make sense to plan for a future where you can accommodate huge bandwidth users without cutting them off.
Core message: Watch out for the leading-edge case users. They might become a large chunk of your business, and if you can't scale to handle them, someone else will for you.
But instead of rail against that, I'll cherish it with the introduction of Ryan's Five Minute Thoughts. Designed to be readable (and writable) during a Youtube video, or (in my case) a build, they are the ultimate in cognitive adaptation.
Today's 5 Minute Thought (5MT): Comcast's Tiered Service.
TimeWarner is introducing tiered internet plans - presumably in an attempt to either restrain bandwidth usage or raise funds to, and this is highly speculative, build a better network. TW claims that 5% of the users consume 50% of the bandwidth usage. Bandwidth usage is surely only going to rise, with the rise of downloadable video from iTMS and Netflix. Right now video downloaders are a leading-edge case of internet users. Bittorrent and iTunes HD downloads is the future of media consumption.
Cable operators are in an interesting position of offering "unlimited" bandwidth that really isn't. Looks like TW has decided this is untenable and decided to take this leading-edge case as exactly that. Right now it's 5% that consumes half, but soon it will be 25% that consumes 99%. At that point you can't realistically cut off a quarter of your userbase. Given the dim outlook for cable companies and subscriber growth it might make sense to plan for a future where you can accommodate huge bandwidth users without cutting them off.
Core message: Watch out for the leading-edge case users. They might become a large chunk of your business, and if you can't scale to handle them, someone else will for you.
Monday, January 07, 2008
Java Programmers
I recently discovered what I called "Java Programmer Syndrome" (JPS) - those developers who did extensive Java programming and are unable to separate the interface and implementation of a data structure. For example, Map vs Tree and hash table. Ask "what is a hashtable" and the answer might be "oh it's like a HashMap but synchronized."
But I am not alone in this, a fascinating paper entitled "Where are the Software Engineers of Tomorrow?" talks about these worrying trends. The conclusion is a weakening math requirement combined with the "assembly" style of Java programming is ruining an entire generation of developers. Choice quote: "We are training easily replaceable professionals."
Demand better CS curricula! Even the ACM is not the answer here - their CS curriculum guide is part of the problem too.
But I am not alone in this, a fascinating paper entitled "Where are the Software Engineers of Tomorrow?" talks about these worrying trends. The conclusion is a weakening math requirement combined with the "assembly" style of Java programming is ruining an entire generation of developers. Choice quote: "We are training easily replaceable professionals."
Demand better CS curricula! Even the ACM is not the answer here - their CS curriculum guide is part of the problem too.
Tuesday, January 01, 2008
Vancouver at Dusk

I got a tripod for christmas. This is the results.
So now that it is January first, I guess a Project 365 update is in order. Basically put, I didn't complete the project. However, according to my metadata I took something like 7-8x as many photos in 2007 as I did in 2006. So something was a success there.
Subscribe to:
Posts (Atom)